柏睿数据+PolarDB湖仓一体联合解决方案
最近几年,随着企业数字化转型大步推进,对数据的综合使用方面,广度、深度、宽度都在不断延伸。为了满足多样化的数据需求,企业数据平台架构也在不断演进。单一数据湖和数据仓库已经不能满足数据分析的发展趋势,越来越多的企业开始尝试基于湖仓一体的混合架构打造自己的企业级数据平台。这种混合架构既有湖和又有仓的技术优势,可以在一定程度上支撑满足企业多样化的数据分析需求。
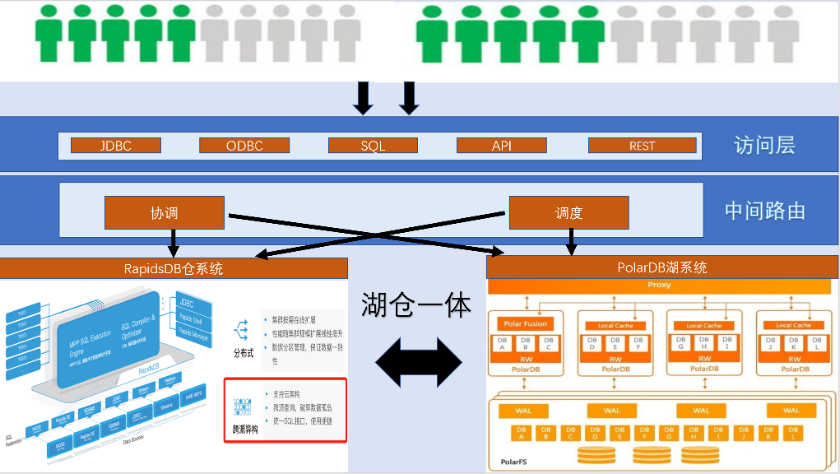
在此背景下,作为阿里云PolarDB开源社区的生态伙伴,柏睿数据和PolarDB联手,根据产品的特殊点整合统一的解决方案,新方案融合数据湖和数据仓库成为一种新型的开放式数据平台架构,PolarDB做湖,RapidsDB做仓,将数据湖和数据仓库的优势充分结合,通过RapidsDB的federation能力构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理、分析和管理功能。
一、柏睿数据介绍
柏睿数据是以自研数据库和人工智能两大产品体系为核心, 服务于数据经济时代的智能数据算力的硬核技术及产品公司。柏睿数据从底 层开始完全自主开发,专注于智能数据算力核心技术突破和产品创新,提供 基于高速计算的海量数据处理智能分析平台和数据存算软硬一体机,以硬核 核心技术支撑,实时、迅捷、高效的挖掘数据价值,助力实现实时+智能的数 字化赋能,为政府智能及国民产业数字化转型升级。
柏睿数据专注于产业数字化赋能,将大数据智能分析平台、数据存算一体机整体的各产业数字化解决方案作为持续深耕发展目标。凭借在数据库系统领域的突破与国际影响力,柏睿数据成为中国自主科技与大数据生态建设中的关键一环与中坚力量,以完全自主可控的国产数据库,通过技术创新与生态建设赋能社会经济数字化转型升级,为中国的产业数字化建设和数字产业化发展提供核心基石技术产品支撑。
柏睿数据核心技术有:
- 高性能数据库技术:采用跨平台、云部署、流式处理 架构、分布式运算、HTAP/AP 的非均衡架构,提供超出业界平均水平 30 倍以 上的数据洞察能力、充分激活客户数据价值。其中流式处理,柏睿数据具有 领先业绩的知识洞察和国际标准的制定能力。
- 面向数据的人工智能技术:利用人工智能算法,敏捷、 主动、牵引数据治理,融合、分析的高效能和便宜性。其中利用 AI 结合大数 据的、数据库内人工智能技术,柏睿数据具有领先业绩的知识洞察和国际标 准的制定能力。
- 面向数据的软硬一体技术:采用存算一体、硬件加速 加密等路线,提供超越竞争对手的芯片级安全性、稳定性、纠错性、一致性, 使得客户的超大规模集群、异地部署、超大用户并发、高速响应都可以同步实现。其中“数据加速加密芯片(板卡)”技术,具有领先业绩的知识洞察和先 人一步的产品研发,相关专利已经在申请中,相关产品也将在 12 到 18 个月 内陆续投放市场。
二、PolarDB介绍
PolarDB是阿里云自主研发的新一代关系型云原生数据库,既拥有分布式设计的低成本优势,又具有集中式的易用性。 • PolarDB 实现了计算节点及存储节点的分离,提供即时生效的可扩展能力和运维能力。 • 简单易用:全面兼容开源数据库MySQL 5.6。 • 高性能:使用RDMA高速网络和分布式计算节点集群,性能最高能达到MySQL的6倍。 • 大容量存储:支持单库容量扩展至上百TB级别,计算引擎以及存储都有秒级扩展能力。 • 快速备份:同一个实例的所有节点都访问存储节点上的同一份数据,数据备份耗时实现秒级响应。 • 一键迁移:实现一键快速迁移,并提供云上的完整生态服务。
阿里云针对PolarDB进行了诸多创新,通过采用存储计算分离、软硬一体化设计,PolarDB实现成本仅为传统商业数据库的十分之一。所实现的计算、内存与存储资源的“三层解耦”架构、多主多写、基于IMCI(内存列存索引)的HTAP、Serverless等功能已是全球首创或业内领先的技术。 从PolarDB发布以来,它在技术和商业化上都获得了迅猛发展,如今已经成为阿里云数据库产品家族中最闪耀的产品。 2021年,阿里云把数据库开源作为重要战略方向,正式开源自研核心数据库产品PolarDB,助力开发者和客户通过开源版本快速使用阿里云数据库产品技术,并参与到技术产品的迭代过程中来。 ▼2021年5月,阿里云率先开源PolarDB for PostgreSQL高可用版。 ▼2021年10月,在云栖大会上,阿里云进一步开源了云原生分布式数据库PolarDB-X和PolarDB for PostgreSQL共享存储版。 ▼2022年10月,PolarDB 系列数据库开源版本全面升级,PolarDB PostgreSQL 本次升级发布,主要集中在数据透明加密、增量备份等企业级特性和数据分片管理、性能线性扩展等分布式特性方面。同时,一体化分布式数据库 PolarDB-X 发布里程碑的大版本 v2.2,主要是金融行业比较关注的国产 ARM 芯片适配、性价比优化和云原生 HTAP 等特性升级。
三、遇到的问题【 业务数据量不断增加】
数据仓库的初衷需求,一个原因主要是数据空间不够用,一个原因是资源竞争,交易应用和分析应用都在一个容器,当任务分派对数据进行使用,两者就会发生竞争关系,导致互相影响,严重会发生交易失败或者分区进程无法获取足够的资源。
所以数据仓库 面对的问题是 业务中的数据需要一个独立的分析环境满足不断膨胀的业务需求。为了满足客户的需求和时代的节奏,数据仓库也演进迭代了多个版本,现在的数据仓库在数据采集、数据传输、数据转换、数据同步、数据存储有了自己的个性化的打造和成熟的技术实现方式。一直秉承传统没有变化的是,数据反复ETL,不停的进行ETL。随着数据进一步的增长,ETL方案的基础上产生了ELT。再随着数据再进一步的增长,产生了数据复制技术。下面我们图示三种技术的区别。
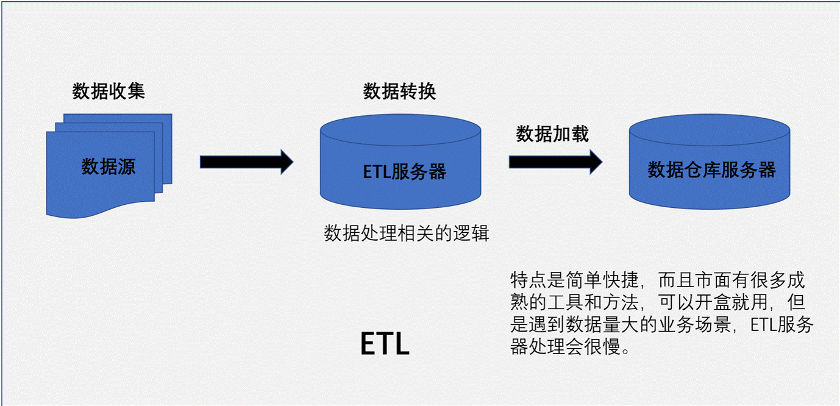
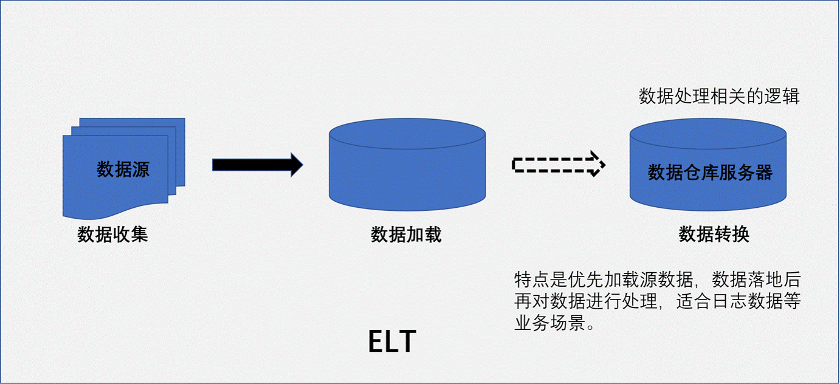
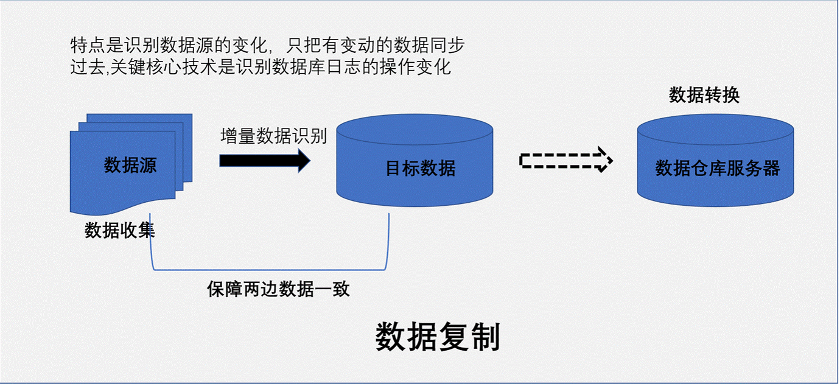
总结三种技术的共性,打通数据孤岛之间的壁垒,底层技术都是数据传输搬送,ETL是先把数据处理后再传输,而ELT是先传输后再处理,即使是数据复制,它能识别数据源的增量变化数据的,也要把数据放到管道 ,根据设定的程序,源源不断同步到目标端,确认数据持久化后才能进一步的处理。三种数据集成模式,各有各的特点和优势。在不同的业务场景,三种模式可以交替使用,互相弥补不足。
大数据时代,数据增长速度远超人们想像,我们说4V ,规模性、多样性、高速性、价值性。 传统的数据集成方式 数据传输和搬送毕竟存在损耗,而且处理流程启动笨重耗时。为了解决数据孤岛问题,把所有的孤岛都装入一个大岛里面,随着业务应用的增多,大岛又变成另外一个数据孤岛。
有没有一种系统架构简洁、访问入口统一、系统集成度更好的解决方案呢?中小企业更偏好什么样的数据库。
四、中小企业如何选用数据库
中小企业选用数据库也希望数据能提供对小表数据高速低延迟的响应能力,除了希望满足海量数据存储能力,也希望数据多种支持大数据的集成解决能力。所以理想中的数据库可以提供以下能力。 • 提供快于磁盘架构数十倍的读写速度,支持高速的随机访问,在无锁表结构的支持下,能够满足大并发下的高吞吐高性能。 • 还提供基于内存计算磁盘备份存储的列式存储架构,支持对超大表进行快速存储计算分析。 • 数据库内置多种算法,讲普通SQL查询语句和复杂关联语句进行编译优化为机器代码,提升分析性能。 • 通过数据联邦的集成能力, 通过创建连接器对不同数据源数据进行跨源访问查询,独创的自适应下推优化技术和即时本机代码编译(JUST-IN-TIME)技术,能优化加速跨源访问查询效率。 • 擅长于OLAP应用场景,同时满足HTAP场景需求,支持MYSQL语法协议,易上手,开发难度小。
通过PolarDB与RapidsDB的federation强强联手,可以发挥更大的威力。
在 RapidsDB 的数据库架构里,数据库联邦是一个逻辑的数据容器。数据库管理员可以在RapidsDB 里根据不同业务场景创建多个联邦(federation)对象,每个联邦对象里面再通过创建不同的数据库连接器(connector)对象,在一个联邦对象中组织来自于 RapidsDB 自身,和通过连接器连接的不同数据源。在通过连接器获得指定的各种数据后,用户就可以对一个联邦对象中的数据执行各种查询语句来进行数据分析工作。
以下图为例,如果一个 RapidsDB 数据库里面有“Engineering”和”Sales”两个联邦对象,那么Engineering 这个联邦对象的数据可以这样表现:Engineering (s1, v1, m1.1),Sales (m1.1,m1.2, s2)。这当中,MySQL这个外部数据源有两个数据库:m1.1 和 m1.2,Engineering 联邦只能够访问 m1.1,而 Sales 能够访问 MySQL的两个数据库。
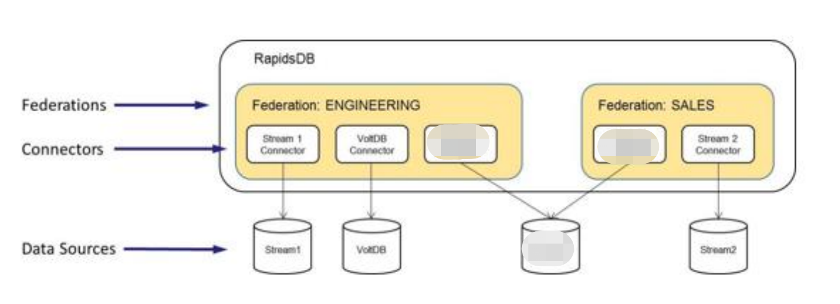
在 RapidsDB 里数据库管理员创建的不同数据库联邦对象,形成了用户能够访问的数据范围 的边界。一个查询语句只能针对一个联邦对象中的数据进行查询,而不能交叉两个或更多 的联邦对象的数据进行查询。
五、基于联邦式的解决方案
柏睿数据的数据联邦是指隐藏底层数据源(关系型数据库、NOSQL、NEWSQL、数据仓库)等技术访问细节,将数据源的抽象和聚合要求将物理资源抽象出来,对外为用户提供一个统一的数据接口。用户在定义数据源的初始化配置文件后,能够自由查询和操作各个目标源的数据源,一言简之,数据虚拟化是基于联邦的云化产品,数据虚拟化技术实现前端与后端多源异构的解耦,轻量级简单解决数据集成多源异构的困难。
数据联邦本身具备核心处理技术,但是容许底下管理数据源保留自治处理的能力。数据联邦集群支持分布、集中、自治与异构,由一批互相协作但保持各自自治性的数据系统组成,类似联邦,中央既统一调控,又保留特殊地区独立自治性。
RapidsDB是一款基于内存的分布式非共享MPP存储和计算构架的分析型数据库,具备完整的数据库管理系统特征,提供高校完备的数据库管理功能。同时具备关系型数据库特征:事务支持、标准SQL支持、标准JDBC驱动。支持高可靠、高可用、高性能。数据联邦上的能力数据源支持MYSQL、Oracle、Postgres、Greeplum、JDBC、Hadoop等 相关产品。 整体上,RapidsDB的技术架构可以分为五层,从下到上依次为: • 存储层:该层包含两个部分,第一个数据源为自有数据源,为柏睿数据自研的分布式内存存储引擎;另一个为其他数据源,RapidsDB依靠跨源异构的查询能力,通过连接器对其他数据源内的数据进行访问,例如:HFDS、Hive、MYSQL等。 • 联邦层:统一实现连接器的创建、管理、使用等功能。 • 执行层:RapidsDB有自己的完全并行的MPP(大规模并行处理)执行引擎,负责执行RapidsDB SQL编译器和优化器生成的查询计划。MPP执行引擎将使用联合连接器访问底层数据源。 • 编译层:RapidsDB有一个高级的SQL编译器和优化器,负责执行用户的SQL查询并构建一个查询计划,充分利用底层数据源的原生SQL功能。所生成的查询计划将下推可由数据源直接执行的部分,然后使用RapidsDB MPP执行引擎执行其余的计划,只需从所需的底层数据源中提取数据以完成查询的执行。 • 服务层:RapidsDB提供了一个命令行界面,即rapids-shell,用于配置连接器和提交查询。同时提供了一个基于Web的管理控制台,即RapidsDB Manager,用于配置和管理RapidsDB群集。
RapidsDB的动态查询优化提供了一个轻便但功能强大的查询动态处理框架,对各种数据源都有广泛的适用性。RapidsDB联邦连接器完全参与优化过程,只需通过同一个SQL语句,一个联邦查询可以充分利用多个底层系统的数据库和数据库模式本身处理数据的能力来加速查询。
由于每一个查询可能涉及到多个数据源,RapidsDB优化器会与连接器交互工作,以确定执行计划中的哪些操作可以下推到哪个底层数据源。给定到连接器的操作会被凝缩成一个由相对应的连接器和数据源负责执行的构建模块。查询计划中没有下推的剩余部分将由RapidsDB执行引擎负责执行。
基于知识库的模型可以使连接器根据底层数据源的不同功能来指导动态优化过程通过动态地在一个凝缩的查询中插入指导性语句,知识库协助连接器收集多源异构数据的统计信息,并将此查询下推到相关底层数据源。
虽然底层的数据源各不相同,但RapidsDB可以让用户在查询数据的时候将不同的数据源集合视作一个单一的数据库系统,并利用标准的SQL来对此联邦视图进行查询。对于一个给定的查询,自动查询优化将帮助ヾ到最佳的执行方式,将工作分配给不同的底层数据源,然后将结果有效整合。这种方式可以简化原本繁复的数据准备工作,让用户可以更专注于数据分析以解决相关的业务问题,而不是将大量时间花费于数据准备或者为了将数据库性能最大化,人工调整查询以适应不同的数据源系统。动态查询优化让多源异构数据的整合变得更灵活与高效。
结语
PolarDB的分布式特性以及存储计算分离架构为其带来了水平扩展、分布式事务、混合负载等能力,新方案融合数据湖和数据仓库成为一种新型的开放式数据平台架构,PolarDB做湖,RapidsDB做仓,将数据湖和数据仓库的优势充分结合,通过RapidsDB的federation能力构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理、分析和管理功能。强强联手,可以发挥出更大的威力。